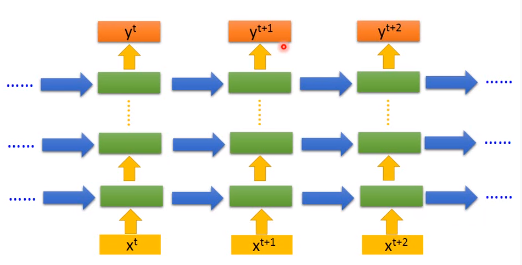
RNN主要是对序列进行记忆化处理
- 把隐藏层的输出会存入内存中
- 内存会作为隐藏层的另一个输入
- RNN会考虑输入序列的顺序
1.RNN示例
一个简单的示例

deep RNN
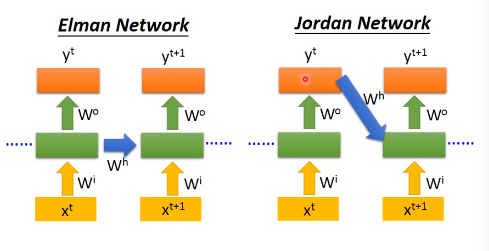
两种不同的网络架构
- Elman Network:存储隐藏层的输出
- Jordan Network:存储最后的输出
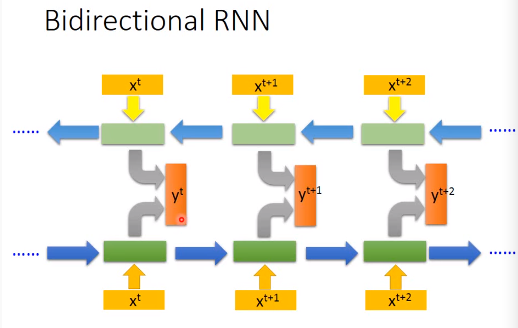
双向RNN
2.Long Short-term Memory(LSTM)
- Input Gate,Output Gate,Forget Gate是通过训练得到的
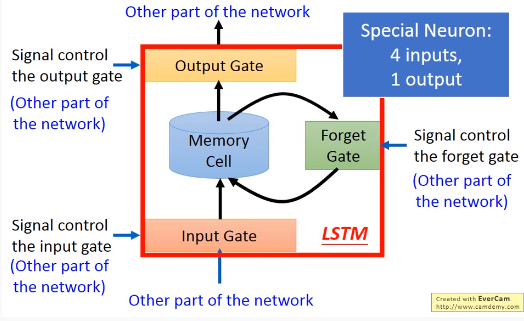
2.1 LSTM计算过程
- 4个输入都是不一样的
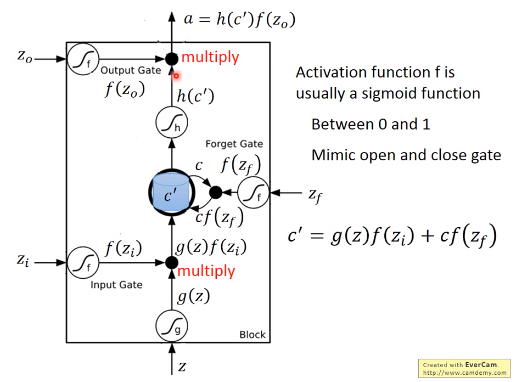
2.2 RNN LSTM
- 先对输$x^t$ 进行变换,得到四个不同的向量$z^f,z^i,z,z^o$,分别作为LSTM的四个输入
- $c^{t-1}$代表控制cell的值
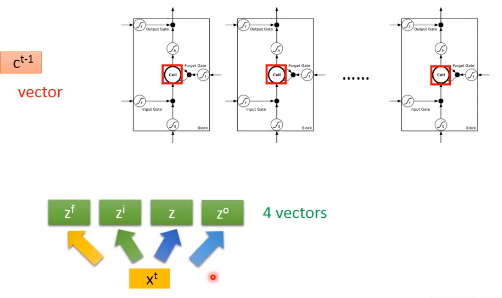
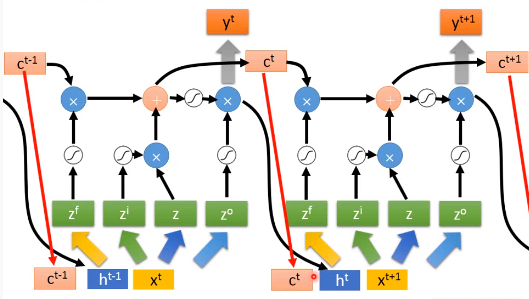
3.RNN的训练
3.1 Loss Function
- 序列中每个元素输入到RNN的输出和参考向量(Reference Vector)的交叉熵(Cross Entrpy)之和
3.2 Backpropagation through time(BPTT)
使用梯度下降方法进行训练
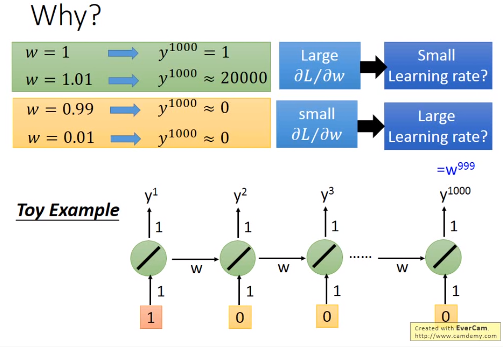
3.3 训练很难
- RNN的error surface(loss function 对参数的变化)在某些地方非常平坦,在某些地方又非常陡峭
- 会导致训练时loss 剧烈震荡
- 有时梯度非常大,会导致参数更新异常
- 这是因为相同的权值在不同的时间点会被反复使用
3.4 解决办法
(1) 设置阈值
设置梯度值的阈值,限制求解的梯度保持在阈值以下
(2) 使用LSTM
- 可以解决梯度消失的问题,学习率设置很小
- 不是所有时间点的memory都会覆盖掉
- memory和input的值是相加的
(3) Gated Recurrent Unit(GRU)
- 旧的不去,新的不来
- input gate打开时,forget gate就会自动关闭
(4)单位阵初始化权值
使用一般的RNN,用单位矩阵初始化隐藏层转移的权值,使用ReLU作为激活函数,效果很好
4. RNN的应用
4.1 Many to One
输入是一个词汇序列,输出仅仅为一个向量
- 语义分析(Sentiment Analysis)
- 关键词提取(Key Term Extraction)
4.2 Many to Many
输入和输出均为系列,但输出更短
- 语音辨识(Speech Recognition)
4.3 Many to Many(No Limitation)
- 机器翻译(machine Translation)
4.4 其他应用
- Syntatic parsing(句法分析)
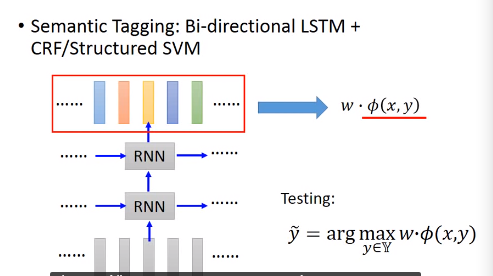
5. RNN VS Structured Learning
5.1 Structured Learning
HMM,CRF,Structured Perceptron/SVM