L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L.Yuille,
“Semantic image segmentation with deep convolutional nets and fully connected crfs,”
arXiv preprint arXiv:1412.7062, 2014.
贡献
-
把DCNNs和概率图模型结合到一起,解决语义分割问题。
-
提出了“atrous algorithm”,提高网络的运算效率。
网络结构
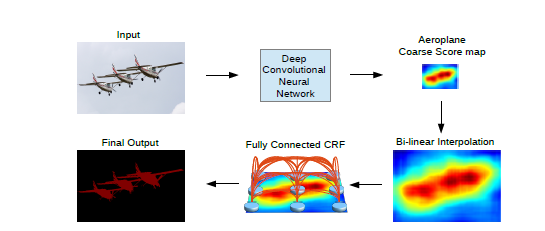
- 本文先将图片通过分类网络进行预测,得到Score map。
- 然后对Score map进行双线性插值。
- 对双线性插值的结果,通过Fully Connected CRF,进一步提高结果的精细度。
1.DCNNs部分
- 对传统分类网络结构进行修改。
- 在最后两层max pooling 后跳过了下采样
- 通过增加 0 ,修改卷积滤波器的尺寸
- 提出了atrous algorithm,可提高计算feature map的效率
- 将传统VGG-16最后的1000路图片分类器替换为21路的分类器
- 控制网络的感受野
- 在将传统分类网络改为全卷积形式后,第一个全连接层有4096个$7 \times 7$ 的滤波期,这会导致昂贵的计算代价。
- 通过对第一个全连接层下采样至$4 \times 4$ ,可显著降低计算时间。
2.恢复精细边界信息
模型深度与边界信息之间存在一种矛盾。模型越深,感受野越大,提取的特征层次更高,越难从feature map种恢复精细的边界信息。在此之前有两个方向解决此问题:
- 融合深度网络中不同层次的信息
- 进行super-pixel 表征,其实相当于解决一个低层次的语义分割问题。
本文提出把DCNNs的结果经过fully connected CRF提取精确的边界信息。
2.1 全连接CRF(Conditional Random Fields)
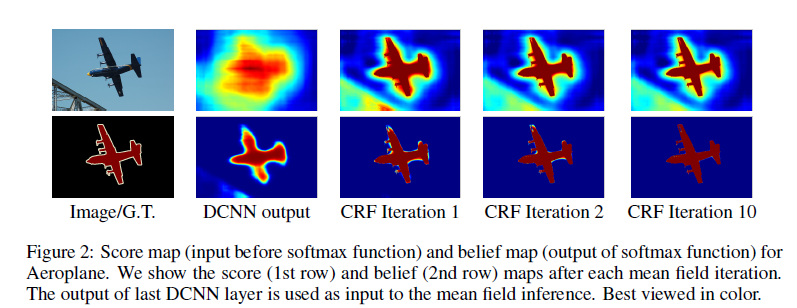
全连接CRF的迭代过程如图所示
能量函数定义如下
- 其中$\bold{x}$ 是像素的标签赋值
- 一元势定义为:$\theta_{i}\left(x_{i}\right)=-\log P\left(x_{i}\right)$,$P(x_i)$是经DCNN计算后在像素i处的标签概率。
- 二元势定义为:$\theta_{i j}\left(x_{i}, x_{j}\right)=\mu\left(x_{i}, x_{j}\right) \sum_{m=1}^{K} w_{m} \cdot k^{m}\left(\boldsymbol{f}{i}, \boldsymbol{f}{j}\right)$
-
$\mu\left(x_{i}, x_{j}\right) = 1$,if $x_{i} \neq x_{j}$,否则为0
-
全连接的意思是图像上每个像素对$(i,j)$都是相连的
-
每个$k^m$都是高斯核,它依赖于对特征$\boldsymbol{f}$进行$w_m$加权,表示为
-
2.2 多尺度预测
将一个两层的MLP附加到前四个max pooling层的每一个的输入图像和输出上
训练
- 训练时将CNN和CRF分开进行训练
- DCNN使用在ImageNet预训练的参数初始化,采用随机梯度下降法对分割任务进行参数微调
- 固定CRF的部分参数,对其他参数进行交叉验证
总结
- 本文把DCNNs和全连接的CRF结合起来,提高了语义分割任务的计算效率和精确度
- 但本文DCNNs和CRF是分开训练的,缺少端到端的训练
- 本文中的“atrous algorithm”为后续DeepLab的语义分割网络的膨胀卷积奠定基础